2025.09.26 日本語特化のLLM AI新興がエヌビディアのサービスとして提供
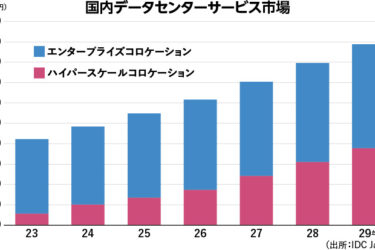
今回発表のものを含む各社のLLMに「広島AIプロセス」について尋ねた回答の比較(出所:エヌビディア)
 ストックマーク製LLMのイメージ。日本語文書を学習した(出所:エヌビディア)
ストックマーク製LLMのイメージ。日本語文書を学習した(出所:エヌビディア)
AI(人工知能)スタートアップのストックマーク(東京都港区)は、日本語に特化した1000億パラメーターのLLM(大規模言語モデル)をゼロから開発し、25日に提供を始めると発表した。米エヌビディアがAIアプリケーションの開発向けに展開するマイクロサービス「NVIDIA NIM」として用意した。
今回のLLMは「Stockmark-2-100B-Instruct」で、エヌビディアが都内で開いたイベント「NVIDIA AI Day Tokyo」で発表した。
具体的には、日本語のビジネス文書や会話文を学習してLLMを構築した。オープンソースの既存LLMを学習させるより、ビジネス特有の文脈や専門用語の面で強みを持つ。
ストックマークはエヌビディアのスタートアップ支援プログラムのメンバーであり、NIMとしての提供に至った。NIMを活用する顧客は、ストックマーク製のLLMを使ったAIアプリケーションを開発できる。エヌビディアのサービスの一環で提供することは、一定の性能や信頼性を確保したことも意味する。
自国の言語や文化、価値観に基づき、国内でコントロール可能な独立した「ソブリンAI」を開発することは、経済安全保障の観点からも重要だ。それだけに、日本発のLLMへの期待感は大きい。
同社の有馬幸介CTO(最高技術責任者)によると、「従来比で推論速度が最大2.5倍向上」したという。有馬氏は発表の意義について、「1000億パラメーター級のAIを誰もが自社の管理下で安全かつ容易に扱えることを意味し、AI活用の裾野を大きく広げるもの」とコメントしている。