2025.06.10 「難読」な日本文書、AIで解析 リコーが開発、7月無償公開へ
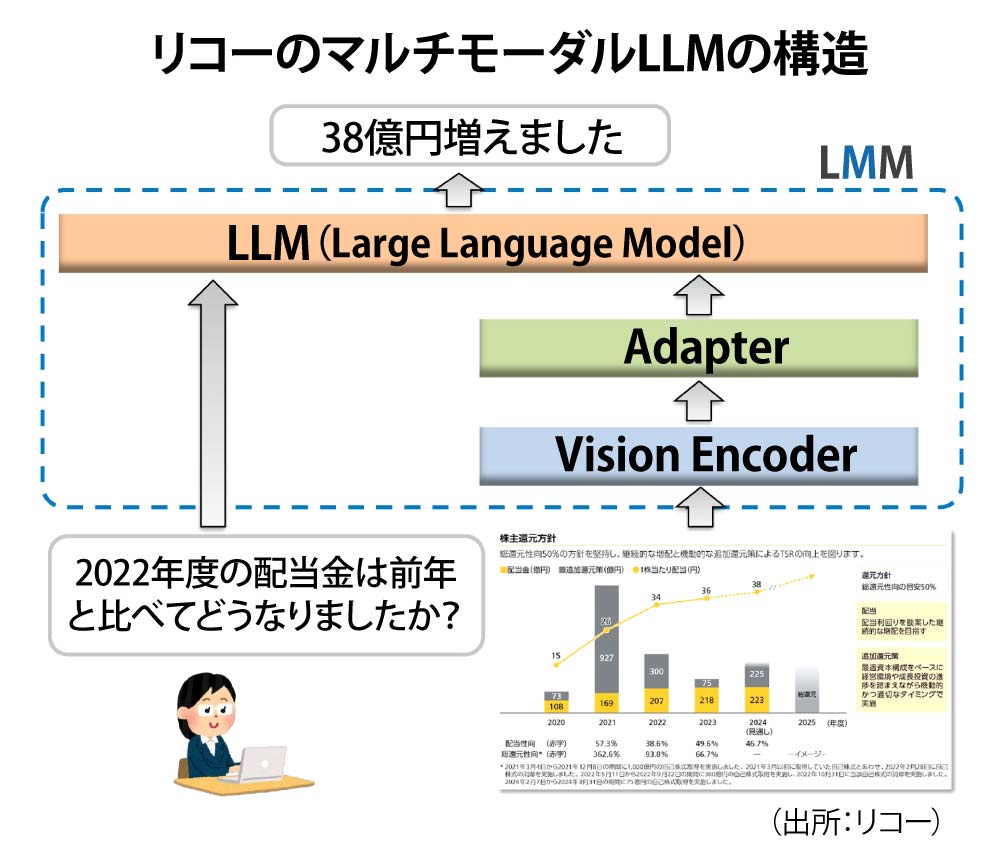
リコーのマルチモーダル大規模言語モデル(LMM)の構造
 リコーの梅津本部長
リコーの梅津本部長
リコーは10日、日本企業の多様なドキュメント活用を目的としたマルチモーダル大規模言語モデル(LMM)を開発したと発表した。日本の企業文書には多数のチャート図やフロー図が含まれ、海外製AI(人工知能)では正しく読解できないケースが多いことから、文書の読み取りに強みを持つリコーが独自に開発。7月にベンチマークツールとして無償公開する予定だ。
リコーは1980年代からAI開発に取り組み、近年は生成AIの研究開発を加速させてきた。一方で、日本企業のドキュメントは多段組みや複雑な図表、フローチャートが多く、従来のAIでは十分に読み解けないといった声が同社に寄せられていた。リコーAIサービス事業本部の梅津良昭本部長は「複雑なレイアウトや多様な図表を含み世界的にも『難読』と言われる日本企業特有の文書形式にAIを活用できるようにすることが開発の原点」と強調する。
独自開発したLMMは、図表を処理するビジョンエンコーダー、出力を言語モデルが理解できる形式に変換するアダプター、統合処理を行う大規模言語モデル(LLM)の3層構造で構成。リコーLMM開発室の長谷川史裕室長は「オープンソースソフトウエア(OSS)として公開されているAIモデル同士を高精度で接続する独自アダプターの開発や、600万枚超の人工生成データを用いた学習手法によって、他のオープンソースモデルを上回る精度を実現した」と説明する。
セキュリティーやプライバシーの観点から社内専用環境でAIを活用したいという企業ニーズにも対応。保険大手の損害保険ジャパンと連携し、同社の保険規定マニュアルなどを用いてファインチューニングした結果、業務特化で精度が大幅に向上した。
リコーは今後、開発した基本モデルと評価環境を無償公開し、日本企業の知の結晶ともいえるドキュメントの利活用を促進する。梅津本部長は「企業の持つ力を余すところなく発揮できるAIとして、業務革新や企業価値向上に貢献したい。今後はさらに複雑な図表や推論にも対応できるよう技術開発を進め、実用化を急ぎたい」と語った。